Wir wollten mal wieder positiver bloggen. Wir wollten mal wieder positiver bloggen. Wir wollten mal wieder positiver bloggen. Wir wollten mal wieder positiver bloggen. Wir wollten mal wieder positiver bloggen. Wir wollten mal wieder positiver bloggen. Wir wollten mal wieder positiver bloggen.
Also gut, bloggen wir heute über Positivität in der Sprache. Und damit Sie sich nicht zu sehr erschrecken oder umgewöhnen müssen: das Nölen bleibt. Flattr drauf!
Wir haben hier schon das eine oder andere Mal über kulturpsychologische Studien berichtet, die komische Annahmen zu Sprache und Kultur machen, auf riesigen Datenmengen basieren und mathematisch robuste, aber unsinnige Korrelationen zwischen Sprache und Gesellschaft gefunden haben wollen (meist handelt es sich um sogenannte spurious correlations). Wie solche Studien konsequent Funktion, Gebrauch und strukturelle Komplexität von Sprache(n) ignorieren, haben wir hier zum Beispiel bei Ego und Pflicht in der Sprache und Gesellschaft oder zum wirtschaftlichen Erfolg in Abhängigkeit von Tempus kommentiert.
Das Problem ist grundsätzlich, dass an solchen Studien nie Linguist/innen beteiligt sind, die mal den Finger heben könnten: „Hust! Stop!“ (offensichtlich fragt man auch im Peer Review niemanden aus der Sprachwissenschaft um Rat). Was solchen Studien dann oft an theoretischer Gültigkeit fehlt, bekommen sie mit großer Medienaufmerksamkeit honoriert. Wir sind materialistischer geworden? Nunja, das ist jetzt zwar kein besonders origineller Vorwurf, passt aber im Frühstücksfernsehen immer gut in die pseudomoralischen fünf Minuten vor dem Sportblock.
Mehrfach war in den letzten Jahren von Studien zum kollektiven Glück (happiness) und gesellschaftlichen Stimmungen (mood) zu lesen, die oft an Daten aus sozialen Netzwerken gemessen werden. Heute soll’s um den Hedonometer gehen, der in „Echtzeit“ positive oder negative Stimmungen auf Twitter einfangen will. Seine Schöpfer/innen haben uns zumindest den hübschen Begriff Hedonometrics beschert. ((von Hedonismus, „in der Antike begründete philosophische Lehre, Anschauung, nach der das höchste ethische Prinzip das Streben nach Sinnenlust und ‑genuss ist, das private Glück in der dauerhaften Erfüllung individueller physischer und psychischer Lust gesehen wird“ (Dudendefinition) ))
Für die Hedonometrie haben die Autor/innen (Dodds et al. 2011, Kloumann et al. 2012) eine Liste der zehntausend häufigsten Wörter erstellt und die Begriffe nach ihrer „Positivität“ evaluieren lassen: man hat Unbeteiligte gebeten, die Wörter auf einer Skala von 1 bis 9 zu bewerten, je nachdem wie „gut“ sie sich bei dem entsprechenden Wort fühlen. Das hat man als „durchschnittlichen Glückswert“ des Wortes interpretiert: laughter ‚Lachen, Gelächter‘ bekam im Schnitt 8,5 und happiness ‚Glück, Zufriedenheit, Fröhlichkeit‘ sowie love ‚Liebe‘ jeweils 8,4. Am anderen Ende der Skala finden sich rape ‚Vergewaltigung‘, suicide ‚Selbstmord‘ und terrorist mit 1,4 bzw. 1,3. Insgesamt überwiegen in der Liste Begriffe mit positiver Bewertung: von 10.222 Wörtern haben nur 29% eine Bewertung von unter 5. Dies veranlasste die Autor/innen dazu, Englisch eine „positive Sprache“ zu nennen, weil es einen „Positivitätsüberhang“ (positivity bias) im Lexikon gebe: die Mehrheit der Wörter sei „positiv“ besetzt — was etwas die Tatsache überstrahlt, dass sich zwei Drittel der Begriffe im Mittelfeld zwischen 4 und 6 befinden. Egal: damit war der Siegeszug durch die Medien nicht mehr aufzuhalten.
Abgesehen davon, dass Wörter in Isolation anders wahrgenommen werden können, als sie tatsächlich verwendet werden — finden Sie cares ‚sorgen, pflegen‘ (7,3) in Who cares? ‚wen juckt’s?‘ besonders zufriedenheitslastig? — übersieht diese Analyse besonders frequenter Elemente die Möglichkeit, dass „negative“ Wörter einfach nur zahlreicher (Typen), aber dafür im Einzelfall seltener sein könnten (Token).
Denn stellen wir uns vor, wir sind gleich oft gut oder schlecht gelaunt: wenn uns für den Ausdruck guter Laune fünf Begriffe zur Verfügung stehen und wir jeden dieser Begriffe jeweils 10 mal einsetzen (50 mal gute Laune), umgekehrt für schlechte Laune aber 25 Begriffe jeweils nur zwei Mal einsetzen (50 mal schlechte Laune), dann befinden sich unter den, sagen wir, sieben häufigsten Begriffen halt beeindruckende 71% „positive“ Begriffe — das sagt aber überhaupt nichts über die Stimmung im Lexikon, der Sprache oder der Sprachgemeinschaft aus. Im Umkehrschluss blieben aber alle potentiell negativen Emotionen unbeachtet, wenn die so definierte „Positivliste“ Ihrer sieben Begriffe die Datengrundlage ist.
Letztendlich ist die Liste, auf der der Hedonometer beruht, im besten Fall also schlicht nichts anderes, als ein Themenbarometer. Und das geht so: man hat die Liste genommen, um die Verwendungshäufigkeit der Begriffe in Milliarden von Tweets mit ihren jeweiligen Glückswerten zu korrelieren. Mit aufwändigsten mathematischen Formeln wurden dann die täglichen Veränderungen in der Verwendungsfrequenz dieser Wörter auf Twitter modelliert. Schauen wir uns zur Verdeutlichung einen Ausschnitt der Stimmungskurve der letzten acht Monate an (Klick vergrößert die Grafik):
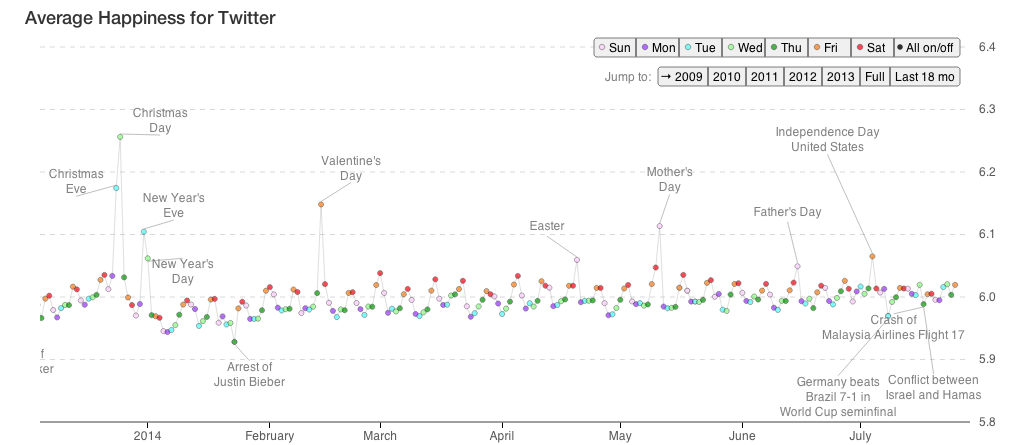
Hedonometrie, 4. Dezember 2013 – 27. Juli 2014, hedonometer.org
Man sieht zwei Dinge: erstens gibt es wöchentliche Zyklen, die samstags ihren Höhe- und dienstags ihren Tiefpunkt erreichen. Zweitens führen Feiertage (wie Weihnachten, Muttertag, Valentinstag, Thanksgiving oder der Amerikanische Unabhängigkeitstag) zu starken Ausschlägen nach oben, und Ereignisse des tragischen Weltgeschehens (Absturz von MH17, Nahost-Eskalation oder der Tod von berühmten Persönlichkeiten) fast ausschließlich zu Stimmungsabfällen.
Man könnte sagen: klingt doch plausibel. Und vermutlich ist das ja nicht mal völlig falsch: am Wochenende sind wir entspannt und zufrieden, am Wochenanfang aber übel gelaunt, was sich wiederum mit der Vorfreude auf das nahende Wochenende bessert. Auch an Feiertagen sind wir happy: Weihnachten, das Fest der Liebe, der Familie und des kollektiven Frohsinns. Und natürlich stürzt ein hohes Ergebnis bei einem WM-Halbfinale Amerikaner/innen in tiefe nationale Trauer.
Wait, what?
(Ich hoffe ja, dass mindestens ein Teil unserer Leser/innenschaft schon über den allgemeinen Entspanntheitsanspruch von Weihnachten gestolpert ist. Falls nicht, fragen Sie jemanden, der mal im Januar eine Singlewohnung in einer deutschen Großstadt suchen musste.)
Das Problem ist, dass man hier eigentlich keinen Zyklus gesellschaftlicher Fröhlichkeit gefunden hat, sondern einer zirkulären Methode aufgesessen ist. Unter den besonders positiv besetzten Begriffen, die am ehesten für die Ausschläge verantwortlich sein dürften (Wert > 7, N = 582, lediglich 5,7% der Begriffe), ((Die ganze Liste kann übrigens hier eingesehen werden.)) befinden sich unter anderem happy, weekend, friends, mother, enjoy, merry, good oder party sowie saturday and sunday und die Feiertage christmas und thanksgiving (sowie independence und valentine’s). Unter den am schlechtesten bewerteten Begriffen (Wert < 3, N = 403, 3,9 % der Begriffe) befinden sich death, accident, murder(er), die/s/d, dead, killed, jail, war, killings, cry/cries, sad, sadness, hate, lost oder funeral.
Wenn man Positivität und Negativität so festlegt und dann damit Fröhlichkeit messen will, findet man lediglich das raus, was man zuvor definiert hat. Zirkulär daran ist, dass abhängigen und unabhängigen Variablen die gleichen Daten zugrunde liegen: ich definiere merry und christmas oder good und weekend als positiv, messe dann, wie oft diese an Weihnachten und am Wochenende artikuliert werden, finde an Weihnachten häufiger Merry Christmas und Freitag/Samstag öfter have a good weekend und folgere daraus, dass Weihnachten ein Freudentag ist und am Wochenende eine fröhliche Gesellschaft auf Partys geht — sprich: es kann gar nichts anderes rauskommen. Das gleiche gilt übrigens für negative Begriffe sowie die Wochentage, deren Positivitätswerte wenig überraschend nahezu komplett dem wöchentlichen Glücklichkeitszyklus entsprechen: monday (4,3), tuesday (5,0), wednesday (5,4), thursday (5,9), friday (6,9), saturday (7,4), sunday (7,3). Hier geht’s schon lange nicht mehr um die Frage, was was bedingt.
Das Problem: solange Elemente Teil der Datenmenge sind, die man voraussagen möchte, dürfen sie nicht gleichzeitig Teil der Voraussage selbst sein. Eigentlich hätte den Autor/innen klar sein müssen, dass die Analyse kaputt ist und dass die abgefahrenen statistischen Modelle wertlos sind, sogar ohne dass sie irgendetwas von Sprachstruktur verstehen müssen. Würde man die zirkulären Begriffe rausnehmen, verschwände die Deutlichkeit (und vielleicht auch die Signifikanz) der Ausschläge. Man kann an einer Tüte mit einzelnen Wörtern (bag of words) — sei sie auch noch so voll oder schillernd visualisiert — keine Emotionen ablesen, da kommt Ihnen einfach zu viel Sprachstruktur, Metaphorik und Idiomatik dazwischen. Fänden Sie die Tatsache, dass morgens häufiger über Sonnenaufgänge gesprochen wird, als über Sonnenuntergänge, kulturpsychologisch interessant? Oder dass Kaffee zwischen 8 und 9 Uhr seinen lexikalischen Höhepunkt hat? Eben.
So gesehen muss die Linguistik da jetzt noch nicht mal mit dem Einwand kommen, dass Sprache eben kein Pool von Befindlichkeiten ist, in den man einfach ein Fieberthermometer stecken kann, um Volkes Stimmung abzulesen — ich tu’s trotzdem mal, sicherheitshalber. Es ist maximal ein Themenbarometer, denn Weihnachten ist vielleicht im ZDF oder der Brausewerbung kollektiv romantisch. Dass wir mit Sprache mehr anstellen, als zu murmeln „I feel good today“ oder „I feel miserable now“ und dass wir mehr als 10.222 Möglichkeiten haben, Emotionen in Worte zu fassen, ist eigentlich offensichtlich, wird in der Kulturpsychologie aber nicht so schnell ankommen. Aber offenbar haben wir — Gott sei Dank! ((Der Spruch ist voll positiv!)) — alle so intakte Familien, dass wir feststehende Ausdrücke wie Happy Independence Day und Happy New Year! aus voller fröhlicher Überzeugung twittern (und nicht, weil man das an diesen Tagen halt so macht). Dann erübrigt sich fürs erste auch zu fragen, wie man No, I don’t hate X & Co hedonometrisiert.
Twitter nennt solche Themencluster unprätentiös „Trends“.
Postscript
An einer Stelle ist den Autor/innen die Absurdität ihrer Analyse zumindest soweit aufgefallen, dass sie es kommentieren:
One arguably false finding of a cultural event being negative was the finale of the last season of the highly rated television show ‘Lost’, marked by a drop in our time series on May 24, 2010, and in part due to the word ‘lost’ having a low happiness score of havg = 2.76, but also to an overall increase in negative words on that date. (Dodds et al. 2011)
‚Ein möglicherweise falsches Ergebnis eines negativen kulturellen Events war das Finale der letzten Staffel der beliebten Fernsehserie „Lost“, das in unserer Zeitreihe am 24. Mai 2010 einen Abfall darstellt; und zum Teil dem niedrigen Happinesswert des Wortes lost, havg = 2,76, aber auch einem allgemeinen Anstieg negativer Wörter an diesem Tag geschuldet ist.‘
Der Einbruch am Tag des 7:1 bei Brasilien gegen Deutschland dürfte weniger der Traurigkeit der Amerikaner/innen, als vielmehr der Kommentarflut zu weinenden Fans (sad, cry), schockierten Aussprüchen wie (no) shit!, schock(ed), sowie der Tendenz, in diesem Fall die Niederlage der Brasilianer (loose, defeat, against [Germany]) sprachlich eher hervorzuheben, als den Erfolg der DFB-Mannschaft (victory, win). Dass das Teil einer messbaren kollektiven Empathie ist, will ich gar nicht bestreiten. Im Gegenteil: das ist für sich genommen sogar ziemlich interessant, was genau in den Vordergrund gestellt wird — und wieso. Aber dann ist die Forschungsfrage halt nicht so kühn.
Literatur
Dodds, Peter Sheridan, Kameron Decker Harris, Isabel M. Kloumann, Catherine A. Bliss & Christopher M. Danforth. 2011. Temporal atterns of happiness and information in a global social network: Hedonometrics and Twitter. PLoS ONE 6(12). e26752. doi:10.1371/journal.pone.0026752.
Kloumann, Isabel M, Christopher M Danforth, Kameron Decker Harris, Catherine A Bliss & Peter Sheridan Dodds. 2012. Positivity of the English language. PLoS ONE 7(1). e29484. doi:10.1371/journal.pone.0029484.
Am Tag des Fußballhalbfinales Deutschland-Brasilien hat die “Operation Schutzrand” der israelischen Armee gegen die Hamas begonnen. Könnte das auch einen Einfluss auf die Häufung von negativen Begriffen an diesem Tag gehabt haben?
Gut möglich, natürlich. Wobei man sehen müsste, inwiefern das auch in der kollektiven Wahrnehmung so plötzlich kam, dass es die Twitterflut zu einem Sportereignis parallel begleitet. Das klingt zynisch, ist aber Twitter.
So viele Möglichkeiten Emotionen auszudrücken und doch fehlen mir gerade die Worte… Und das von einem Department of Mathematics and Statistics! Da sollte man doch zumindest… ach, egal…
Das… das macht mich alles andere als glücklich (und das Hedonometer würde es nicht mal verstehen). So viel dann auch zur Überschrift… ;-/
Vielleicht hätten die Autoren der Studie weniger komplexe Konzepte zur Prüfung bereit halten sollen, sagen wir, die Qualia von Farben bzw. deren Bezeichnungen. Oder sie hätten nicht Ausdrücke nehmen sollen, die bezeichnen, was gesucht ist, sondern schauen, welche Farben positiv und negativ konnotiert sind.
Oder sie hätten dem alten Grundsatz folgen sollen, dass je ausgefeilter — abgefahrener — die statistischen Methoden, desto fragwürdiger die Ergebnisse.
Der Name Bliss passt irgendwie zur Studie. Wenn das Peer Review dort so streng ist, veröffentliche ich doch auch einmal ein paar Studien auf Plos One.
PS: Temporal Patterns, nicht atterns.
@Daniel: Damit wäre ich vorsichtig. Ich denke, das Problem ist eher, dass für den Review häufig Statistiker/innen eingebunden werden, bzw. also Menschen, die aus der gleichen Disziplin wie die einreichenden Autor/innen kommen (bzw. deren „Hauptdisziplin“). Ich weiß aus eigener Erfahrung, dass es als Linguistin bei nicht-sprachwissenschaftlichen Zeitschriften schwer ist (wobei das immer so ist, nehme ich an, wenn man fachfremd ist). Da das Problem von „Culturomics“ vor allem in der Theorie liegt bzw. den Annahmen über Sprache, die vor der Methodik liegen, ist das auch kein Problem von PLOS ONE allein, sondern findet sich in allen Bereichen und allen Zeitschriften, d.h. den Operationalisierungsfehler begehen viele — weil er ihnen als Fehler nicht bewusst ist.
“übersieht diese Analyse besonders frequenter Elemente die Möglichkeit, dass „negative“ Wörter einfach nur zahlreicher (Typen), aber dafür im Einzelfall seltener sein könnten (Token).”
Vielleicht verstehe ich das nur nicht richtig, aber müsste es dem Beispiel im auf das Zitat folgenden Absatz zufolge nicht genau umgekehrt sein? Weniger Typen, mehr Token?
@Ospero: keine Ahnung, auf wessen Seite jetzt grad das Missverständnis liegt (und ich die Frage richtig verstanden habe): angenommen eine Sprache hat 100 Wörter (Typen), wovon 5 positiv, 25 negativ und 70 neutral bewertet sind. Die fünf positiven Wörter haben eine hohe Tokenfrequenz von jeweils 5, die 25 negativen Wörter kommen aber jeweils nur ein mal vor. Dann könnte ich in einem Sample beispielsweise 50 emotional gefärbte Token haben (positiv: 5 Typen, 25 Token; negativ: 25 Typen, 25 Token). Dann hab ich genau gleich viel über Positives und Negatives gesprochen — aber in eine Analyse, die nur hochfrequente Einheiten untersucht, gehen nur hochfrequente, hier: positive, Typen ein.
Ah, jetzt…das Missverständnis war auf meiner Seite. Kontext hilft. 😉
Interessante Dekonstruktion, solche Häufigkeitsanalysen sind mir bei meiner Literaturrecherche auch schon ein paar mal aufgefallen.
Zu Analysen mit Daten aus Sozialen Medien (insb. georeferenzierten Daten) habe ich einen längeren Blogpost geschrieben, der weitere Probleme aufzeigt, z.B. die “participation inequality”, die das (sonst schon wertlose) Resultat sicher auch bei Sprachanalysen beeinflusst.
Den Post findest Du unter http://timogrossenbacher.ch/2014/04/truth-and-beauty-in-social-media/
Immer wieder interessant, was so alles untersucht wird, wenn der Tag lang ist. Allerdings hätten mich die Worthäufigkeiten auch ohne die Analysen dieses Blogs nicht überrascht. Wo sehen denn die Autoren der Untersuchung die Relevanz der Ergebnisse des Hedonometers? Oder ist das nur eine Spielerei?